


AIは人間の言葉を理解しているのか?
何か調べ物をしようと思うと、今やウェブ検索するのと同じくらいの感覚でAIに尋ねる人も増えてきている。しかしAIは私たちの言葉を果たして理解して答えを出力しているのだろうか。AIの中でも、特に自然言語処理技術の評価について研究を進める国立情報学研究所 コンテンツ科学研究系 菅原朔助教の講演「AIは人間の言葉を理解しているか?」(大学共同利用機関シンポジウム2024/2024年11月9日)を紹介する。



答える人:菅原 朔 助教(国立情報学研究所)
すがわら・さく。国立情報学研究所 コンテンツ科学研究系 助教。東京大学大学院情報理工学系研究科を修了し、2020年より現職。専門は自然言語処理、計算言語学。
“大規模言語モデル”とは
ここ数年、ありとあらゆる分野においてAIの存在感は日増しに高まっている。中でも人間の言葉を機械で処理する「自然言語処理」を行うものは、私たちの日常にすっかり浸透したと言っても過言ではないだろう。「このような技術は、これまでのいろいろな蓄積の上にできています。2022年にチャット形式で使えるようなインターフェースが出たのが大きなマイルストーンだったとは思うのですが、ブーム自体は2013年ぐらいから始まっています。そこからだんだんと人間が使う言葉をコンピュータ上で取り扱いやすく、表現しやすくなりました。ただ、ブレイクスルーとしてはチャット形式で使えるようなサービスが出たというのが大きかったのかなと思っています」と菅原さんは話す。入力された文章に対してそれに続く単語を予測するのが、言語モデルの根本的な仕組みである。近年大活躍中の自然言語処理技術は“大規模言語モデル(LLM)”と呼ばれるものだ。「具体的にはニューラル言語モデルと呼ばれます。ある文章をニューラルネットに入力すると、ニューラルネットは入力文章に続く単語を確率分布として出力するというのが基本的な仕組みです」(菅原さん)。
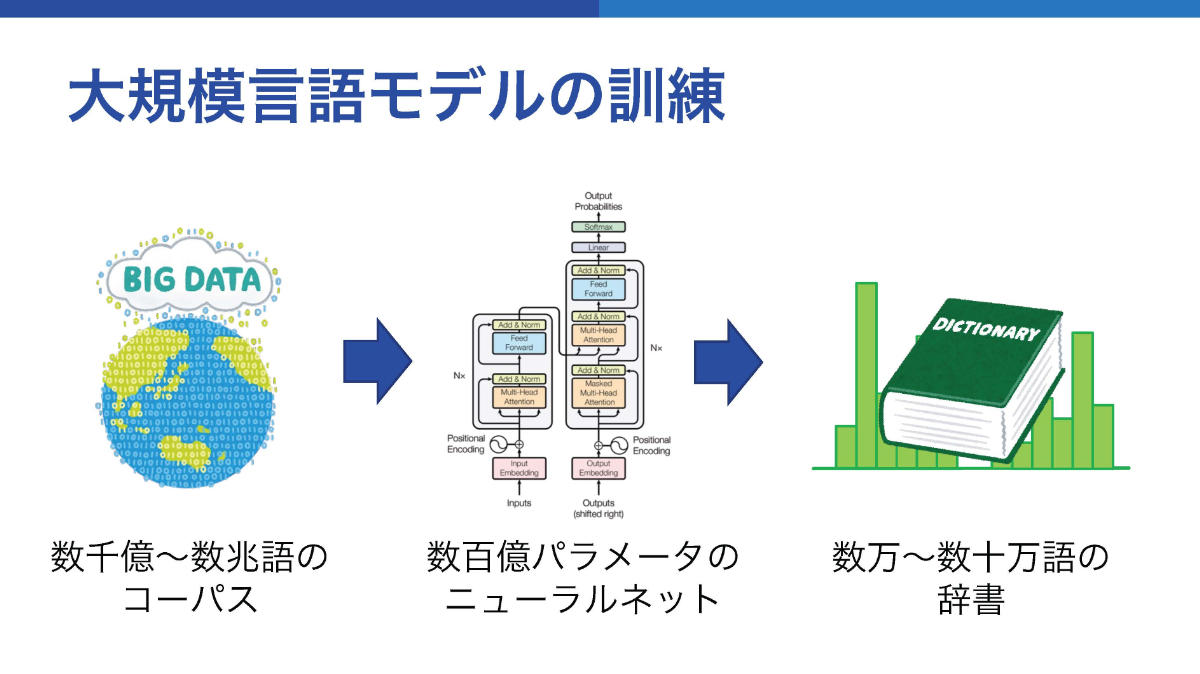
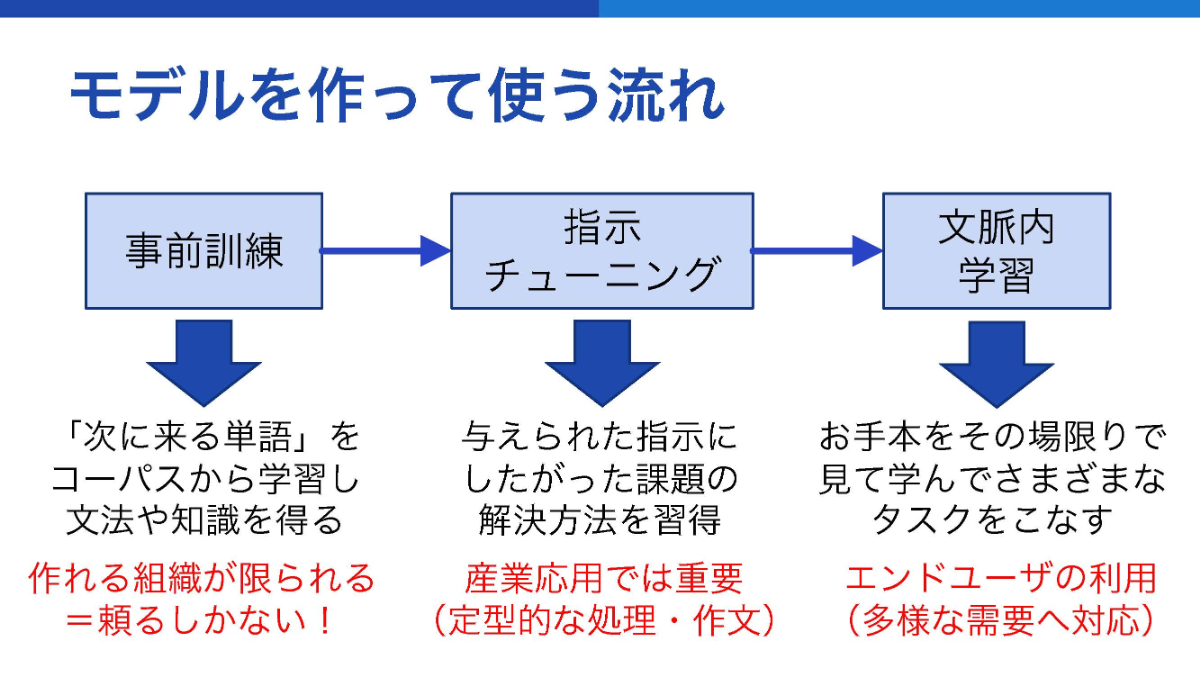
ただ、狙った単語を出力できるようにするためには、ニューラルネットを訓練しなければならない。そのために必要となるのが、膨大な量の“言葉”である。数千億から数兆という量の単語からなる「コーパス」と呼ばれる言葉のデータがある。それをニューラルネットに送り、ニューラルネットの数百億のパラメータをチューニングすることで出力の性能を向上させる。この訓練を通じて、数万から数十万語の辞書のもとで適切な出力ができるようになるという。次の単語を予測するための文法や知識を得るために行うトレーニングには、大きく3つのフェーズがある。最初に行うのが事前訓練(プレトレーニング)だ。これはモデルを構築する段階で行うもので、必要とされる計算コストの大きさから訓練を実行できる組織は限られる。次に行うのは指示(インストラクション)チューニングと呼ばれる、特定の指示に特化させたパラメータの調整フェーズだ。例えば翻訳、文章の要約、質問への応答など、それぞれの指示に応じた出力を調整することができる。そして最後が文脈内学習(インコンテクストラーニング)と呼ばれる、わずかな例を入力時に与えることにより、出力時の応用を促すというものとなる。
AIを評価するのは難しい
ここまでの話を聞くと、大規模言語モデルはこちらの入力に対して膨大な学習に基づいて応用した返事を出力できる賢いシステムだと思われるかもしれない。しかし、時には“もっともらしく間違ったことを言う”こともあると、菅原さんは続ける。「例えば、『今回のシンポジウム会場までのアクセス』というマイナーな情報について尋ねてみると、さも正しそうに嘘の情報を返してきます。これを正しく評価するためには、システムが出力するアウトプットが入力に対してどうできていないかを指摘しなければいけないのですが、実はそれが難しいのです」。自然言語処理分野はもともと分類や識別的なタスクを大規模な訓練データに基づいて行うものであり、文章を自由自在に生成するようなものではなかった。ところが、徐々に生成的な文章や訓練データの乏しい事例に基づく出力、さらには横断的なタスクを課すような使い方が増えてきている。これこそが、評価を難しくしているポイントだと言う。
菅原さんによると評価の難しさは、代表的に3つに分解できるという。一つ目は「自動評価が難しい」点、二つ目は「何を指標に評価するのかが自明ではない」点、そして三つ目は「高いコストがかかる」点である。まず一つ目の「自動評価の難しさ」だが、例えばあるシンポジウムの日本語による概要文を英語に翻訳してから再度日本語へと逆翻訳させ、元の日本語文と逆翻訳の出力を比較したときにどれほど正しいか評価しようとする。「全体としては同じような表現であるものの、細かく見れば『このシンポジウム』が『本シンポジウム』になっていたり、『発表』が『紹介』となっていたりと、違う表現がたくさん出てきます。ぱっと見るとほぼ一緒なので正解と言いたいところですが、それをコンピュータに大量にやってほしいとしても評価の方法が自明ではありません。文章の長さも変わりますし、どことどこを比べるか指し示すことも難しい。そこで最近は絶対的な評価ではなく、どちらの方がよりまともかをより強い大規模言語モデルに評価させるという“相対的評価”をさせることが流行っています」(菅原さん)。ただ、モデルがくだす判定に癖があることを指摘する研究もあると、菅原さんは続ける。「ポジションバイアスと呼ばれる、回答を提示する順番によって応える結果が変わるようなものや、内容はともかく長く、細かく書いてあるように見える文章をいい回答だと評価するような傾向が指摘されています。さらには、同じような言語モデルを用いて生成された文章の方が良いと判断しやすい、などというナンセンスな癖もあったりします」。解決法は、バイアスがないような評価をする工夫を地道に続けるほかないようだ。

次の「何を指標にするか」については、システム同士を比較して何が得意・不得意かを判断することの難しさがある。「入力された問いに答えるためにどんな能力や知識が必要か、元々の問いに書かれている訳ではありません。つまりは共通の『通知表』のようなものがないため、同じ問いに対するシステム同士の比較がしづらいのです。また、内容があっているかどうか以前に出力の文法的な正しさや流暢さといった側面も指標に加えるかどうか、といった課題もあります」(菅原さん)。そして最後の「高いコスト」だが、出力させる内容が難しくなっていけばいくほど、人の手で単純に評価するにしても自動的な評価をするために毎回言語モデルを用いるにしても、結局お金と時間が必要となることは言うまでもないだろう。
AIによる“理解”とは何なのか
今や、なんでも聞けば答えてくれる存在と思われがちな大規模言語モデルだが、結局のところ人間の言うことを理解しているのだろうか。人工知能の“知性”を判定する方法の一つに「チューリングテスト」と呼ばれるものがある。これはAIか機械かわからない状態の相手と審査員がやりとりを行い、審査員から相手が機械だと見抜かれずに会話が続けば合格、と言うものだ。2024年春にChatGPTがチューリングテストをパスできると主張する論文が出されたが、これでAIによる理解が示されたかといえば必ずしもそうとは言えない。歴史的には、いろいろな批判もなされている。「言語理解には、表現を現実世界の対象と対応づけることが必要だという考えもありますが、たとえ対応づけができていなくても、やり取りの中で相手がまるで言語を理解しているように思うことだってあります。これこそが理解だという定義を専門家が言いきるのも変な気がするし、みんながある程度理解してるんじゃないかと思ってしまえばそれでもいい気がします。言語理解に対して必要条件や十分条件を決められるような気はあまりしないと個人的に感じています」と菅原さんは話す。

今後はますますAIの振る舞いが“賢く”なるだろう。入力も文字だけでなく音声や映像などさまざまなセンサ情報を認識するようになるだろうし、その利用の幅もますます増えるに違いない。その中で、AIの“理解”に対する評価について迫る取り組みは続く。「まずは『何を測るか』ですが、人間が持つ社会的な能力に“心の理論”といって、他者が自分とは異なる視点や考えを持っていることを想像できるかというものがあります。今の言語モデル的なシステムが果たしてどうなのかを評価する研究が徐々に出てきています」(菅原さん)。また言語獲得能力についても注目されているようだ。人間の言語学習は12歳くらいまでにおよそ1億語の言語的インプットを使って行うのに比べ、現在の大規模言語モデルは何桁も多い言語データを用いて学習している。この非効率な状況をどのように効率化するかという方向性の研究も進んでいると言う。そして、これらをどうやって測るのかの参考となるのは、どうやら人間の振る舞いらしい。「人間の心理学的、教育学的な振る舞いを研究する分野として心理測定学という分野があります。この“人間の振る舞い”を評価するノウハウを、AIの振る舞い評価に結びつけながら研究を進めていければと思っています」。AIはアウトプットするものだけでなく、その評価の方法までどんどん人間らしくなっていくのかもしれない。
(文:科学コミュニケーター 本田隆行 公開日:2025/3/25)